 Aschach hydro-power plant, Austria (source Wikopedia, Kraftwerk Aschach 1.jpg)
Aschach hydro-power plant, Austria (source Wikopedia, Kraftwerk Aschach 1.jpg)
Hydrological data and Hydropower
Using C3S EFAS data to estimate run-of-river generation
Modelling (and thus understanding) the generation of renewable energy sources is very important, especially considering their link with meteorological variables. In this blog post I would like to focus on run-of-river hydropower, a common source of electricity in Europe.
This notebook demonstrates the potential in using free/open data to analyse & model run-of-river generation. I will use three different datasets:
- The JRC Open Power Plants Database (JRC-PPDB-OPEN) to know the coordinates of the most important plants in Europe. The dataset is open and it can be downloaded from this link
- The time-series of the single units from the ENTSO-E Transparency Platform. The Transparency Platform can be accessed from the website or via SFTP after a registration
- River discharge historical data from the European Flood Awareness System (EFAS) available on the Copernicus Data Store. The data is freely available after a registration.
I cannot share the entire workflow because the size of the datasets used is too big: except for the JRC-PPDB-OPEN the other two are more than 50 GBs.
Coordinates and generation time-series
The first step is to extract from the Transparency Platform the time-series of the largest run-of-river plants in Europe, finding then their coordinates using the JRC-PPDB-OPEN.
From the power plants database we get the 20 run-of-river power plants
with the highest installed capacity (capacity_p).
units <- read_csv("JRC-PPDB-OPEN.ver0.91/JRC_OPEN_UNITS.csv",
col_types = cols(
eic_p = col_character(),
eic_g = col_character(),
name_p = col_character(),
name_g = col_character(),
capacity_p = col_double(),
capacity_g = col_double(),
type_g = col_character(),
lat = col_double(),
lon = col_double(),
country = col_character(),
NUTS2 = col_character(),
status_g = col_character(),
year_commissioned = col_double(),
year_decommissioned = col_double()
)
) %>%
dplyr::filter(type_g == "Hydro Run-of-river and poundage") %>%
distinct(name_p, .keep_all = TRUE) %>%
arrange(-capacity_p) %>%
select(eic_p, eic_g, name_p, country, capacity_p, lat, lon, status_g) %>%
top_n(20, capacity_p)
kable(units)
| eic_p | eic_g | name_p | country | capacity_p | lat | lon | status_g |
|---|---|---|---|---|---|---|---|
| 30W-CHE-PDF1—A | 30WHIDRPDFE3—H | HPP Portile de Fier I | Romania | 1161.0 | 44.673 | 22.532 | COMMISSIONED |
| 34WEHP-DJE-1—R | 34WEHP-DJE-1G3-L | HE DJERDAP I | Serbia | 1098.9 | 44.668 | 22.527 | COMMISSIONED |
| 43W-PLAV-HPP—J | 43W-PLAV-HG4—U | Plavinas HPP | Latvia | 894.0 | 56.583 | 25.239 | COMMISSIONED |
| 24WV–HGA——8 | NA | Gabčíkovo | Slovakia | 720.0 | 47.880 | 17.538 | COMMISSIONED |
| 26WIMPIGROSIO-11 | 26WPREM-GROSIO10 | GROSIO | Italy | 655.0 | 46.286 | 10.265 | COMMISSIONED |
| 48WSTN00000CRUAC | 48W000000CRUA-40 | CRUA | United Kingdom | 440.0 | 56.394 | -5.115 | COMMISSIONED |
| 17W100P100P0319C | NA | GENISSIAT | France | 420.0 | 46.053 | 5.813 | COMMISSIONED |
| 34WEHP-BBASH—V | 34WEHP-BBASHG4-M | HE BAJINA BASTA | Serbia | 420.0 | 43.965 | 19.410 | COMMISSIONED |
| 43W-RIG-HPP—-1 | NA | Riga HPP | Latvia | 402.0 | 56.950 | 24.105 | COMMISSIONED |
| 26WIMPIORTICA-13 | 26WUUUUUORTICA1F | TIMPAGRANDE | Italy | 395.0 | 39.176 | 16.781 | COMMISSIONED |
| 48WSTN00000FFESK | 48W000000FFES-1S | FFES | United Kingdom | 384.0 | 53.118 | -4.103 | COMMISSIONED |
| 17W100P100P0324J | NA | DONZERE MONDRAGON | France | 348.0 | 44.304 | 4.742 | COMMISSIONED |
| 14W-BAW-KW—–F | 14W-BAW-TU—–V | Altenwörth | Austria | 328.0 | 48.375 | 15.855 | COMMISSIONED |
| 26WIMPITOADDA-1T | 26WUUUALTOADDA15 | VENINA | Italy | 327.0 | 45.441 | 12.316 | COMMISSIONED |
| 48WSTN00000FOYEQ | 48W000000FOYE-22 | FOYE | United Kingdom | 320.0 | 57.246 | -4.490 | COMMISSIONED |
| 17W100P100P0323L | NA | MONTELIMAR | France | 295.0 | 44.593 | 4.726 | COMMISSIONED |
| 14W-BGS-KW—–Q | 14W-BGS-TU—–5 | Greifenstein | Austria | 293.0 | 48.355 | 16.242 | COMMISSIONED |
| 17W100P100P0302T | 17W100P100P0049F | CHASTANG | France | 293.0 | 45.151 | 2.010 | COMMISSIONED |
| 14W-BAS-KW—–I | 14W-BAS-TU—–Y | Aschach | Austria | 287.4 | 48.385 | 14.023 | COMMISSIONED |
| 34WEHP-DJE-2—M | NA | HE DJERDAP II | Serbia | 270.0 | 44.302 | 22.562 | COMMISSIONED |
Then I have extracted the generation time-series from the Transparency Platform. This dataset can be explored and downloaded directly on the website in the section Actual Generation per Generation Unit. Obviously, if you need all the historical data of multiple plants, the only option is the bulk download via SFTP (in principle, this can be achieved also through the restful API provided but I have never tried).
From the SFTP you will obtain a bunch of CSV
files, one for each month of data. From this tabular data the needed
plants can be extracted filtering the rows where the EIC
code of
the unit (GenerationUnitEIC) is in our list (eic_g column). A final
postprocess is needed: the data in the Transparency Platform is hourly
while the hydrological data we will use in the next step is daily, then
the time-series are aggregated at daily level obtaining the data in MWh.
I have extracted the data in a tibble and saved to a CSV file (you can download it from this link ).
entsoe_tp_data <- read_csv("ENTSOE-TP-time-series-top-20-ror-europe.csv",
col_types = cols(
date = col_date(format = ""),
eic_g = col_character(),
output = col_double()
)
) %>%
group_by(eic_g) %>%
summarise(
`number of daily samples` = n(),
`average daily generation (MWh)` = mean(output, na.rm = TRUE)
)
kable((entsoe_tp_data))
| eic_g | number of daily samples | average daily generation (MWh) |
|---|---|---|
| 14W-BAS-TU—–Y | 1659 | 4317.5324 |
| 14W-BAW-TU—–V | 1659 | 5256.2183 |
| 14W-BGS-TU—–5 | 1659 | 4574.5451 |
| 17W100P100P0049F | 1388 | 386.1680 |
| 26WPREM-GROSIO10 | 1707 | 4015.5589 |
| 26WUUUALTOADDA15 | 1707 | 1275.6479 |
| 26WUUUUUORTICA1F | 1676 | 1474.2351 |
| 30WHIDRPDFE3—H | 1696 | 2266.5841 |
| 34WEHP-BBASHG4-M | 5 | 859.5000 |
| 34WEHP-DJE-1G3-L | 5 | 2309.1160 |
| 43W-PLAV-HG4—U | 1709 | 604.6829 |
| 48W000000CRUA-40 | 1038 | 247.5113 |
| 48W000000FFES-1S | 826 | 196.4877 |
| 48W000000FOYE-22 | 1225 | 721.9635 |
Although we have selected the 20 power plants with the highest capacity in the JRC-PPDB-OPEN, in the Transparency Platform we could find the time-series for only 14 power plants (and two of them have only 5 samples).
The rest of this post will focus only on one plant, but the shown procedure can be applied in batch to multiple plants.
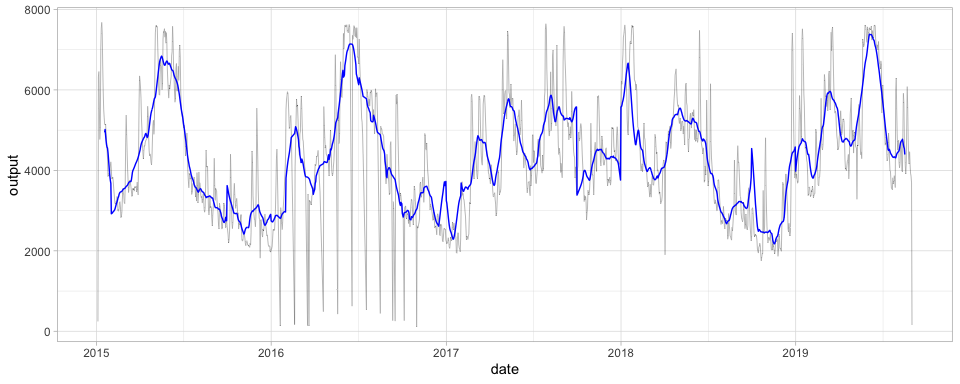
Let’s visualise the daily generation time-series for the Aschach hydro-power plant on the Danube in Austria. In the following figure we can see the daily generation (black line) and the rolling average for 30 days (blue line).
selected_plant <- read_csv("ENTSOE-TP-time-series-top-20-ror-europe.csv",
col_types = cols(
date = col_date(format = ""),
eic_g = col_character(),
output = col_double()
)
) %>%
dplyr::filter(eic_g == "14W-BAS-TU-----Y") %>%
ggplot(aes(x = date, y = output)) +
geom_line(size = 0.1) +
geom_line(aes(y = zoo::rollmean(output, k = 30, fill = NA)), color = "blue") +
theme_light()
print(selected_plant)
River discharge from EFAS and its correlation with the generation
As specified in the dataset
page,
the EFAS historical data provides estimate of river discharge from 1991
with a resolution of 5 km. Using Python and the powerful xarray
module we can open the entire EFAS
dataset and extract the the time-series for a single power plant. Given
that the coordinate of the power plant can be inaccurate, I don’t select
the grid point containing the power plant’s coordinate but also the 8
neighbours, then for each time step, selecting the maximum discharge of
those 9 grid points.
The Python code is available on this Github gist.
Now, let’s go back to the Aschach hydro-power plant. The Python script saved the time-series of the river discharge in the coordinate 48.385, 14.023 in a CSV file. Now we can join the generation data with the river discharge.
sel_unit <- units %>% dplyr::filter(eic_g == "14W-BAS-TU-----Y")
generation_data <- selected_plant <- read_csv("ENTSOE-TP-time-series-top-20-ror-europe.csv",
col_types = cols(
date = col_date(format = ""),
eic_g = col_character(),
output = col_double()
)
) %>%
dplyr::filter(eic_g == "14W-BAS-TU-----Y")
discharge_data <- read_csv(sprintf("out-%s_2010-2018.csv", sel_unit$eic_p),
col_types = cols(
time = col_datetime(format = ""),
step = col_character(),
surface = col_double(),
valid_time = col_datetime(format = ""),
dis24 = col_double()
)
) %>%
select(time, dis24) %>%
mutate(time = lubridate::floor_date(time, "days") %>% lubridate::as_date())
joined_data <- inner_join(
generation_data,
discharge_data,
by = c("date" = "time")
) %>%
dplyr::filter(!is.na(output), !is.na(dis24))
kable(head(joined_data))
| date | eic_g | output | dis24 |
|---|---|---|---|
| 2015-01-04 | 14W-BAS-TU—–Y | 244.0 | 1171.059 |
| 2015-01-05 | 14W-BAS-TU—–Y | 6326.7 | 1272.953 |
| 2015-01-06 | 14W-BAS-TU—–Y | 6454.2 | 1220.108 |
| 2015-01-07 | 14W-BAS-TU—–Y | 5527.0 | 1142.998 |
| 2015-01-08 | 14W-BAS-TU—–Y | 4770.6 | 1075.707 |
| 2015-01-09 | 14W-BAS-TU—–Y | 5055.8 | 1296.062 |
Now we can visualise the two time-series, applying a normalisation because they have two different unit measures: MWh for the generation and cubic meters per second for the river discharge.
compare_plot <- ggplot(
data = joined_data %>%
select(date, generation = output, discharge = dis24) %>%
gather(variable, value, -date) %>%
group_by(variable) %>%
mutate(value = scale(value)),
aes(x = date, y = value, color = variable)
) +
geom_line() +
theme_light()
print(compare_plot)
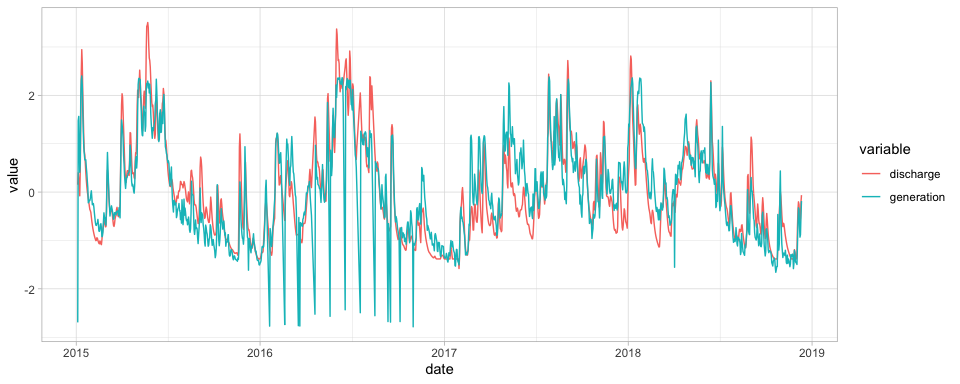 The
Spearman correlation of the two variables is 0.88 and also the plots
shows the level of their correlation. And the correlation is also high
for many other power plants, for example for Laufenburg hydropower
station is even 0.92.
The
Spearman correlation of the two variables is 0.88 and also the plots
shows the level of their correlation. And the correlation is also high
for many other power plants, for example for Laufenburg hydropower
station is even 0.92.
What are the potential applications?
- For power system modeling this means that we are able to estimate the generation of run-of-river power plants with also the possibility to create a synthetic dataset for the entire EFAS historical timespan (1990-2018)
- Also, we can extend this correlation to the climate change scenarios to simulate the generation of run-of-river in different scenarios (and for different models)
- Weather and seasonal forecasts might be used to provide(operational) forecasts of run-of-river generation (not an easy task though)